TCP 数据的发送与接收
写在前面
TCP 数据的发送与接收是个很大的话题,拖了很久也想不到好的切入点。这部分可以简单分为「超时重传」、「窗口管理」以及「拥塞控制」三个主要部分。掉书袋的话恐怕会让这篇文章被束之高阁(每写一道数学公式就会失去一半读者),所以这篇文档对具体算法只谈思想不谈公式,然后佐以代码或命令来验证实现细节。
TCP 超时重传
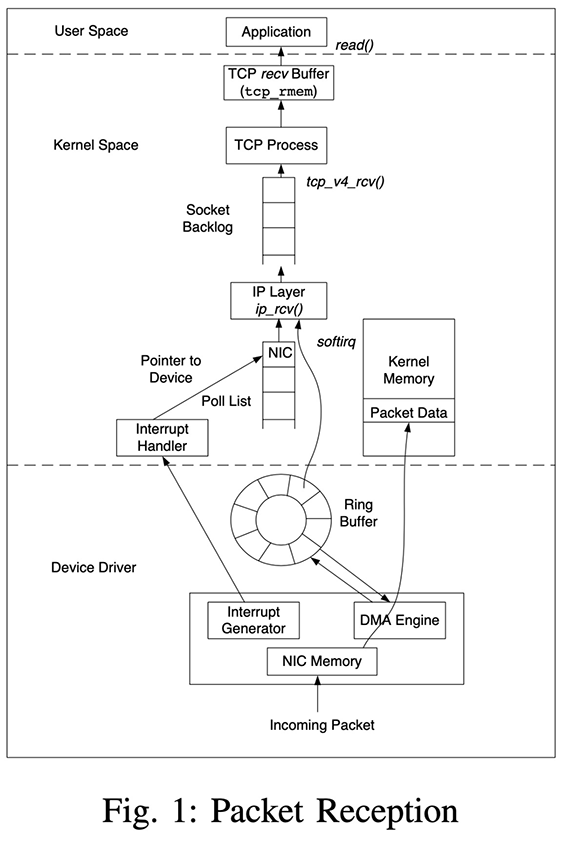
理解 TCP,就是理解如何在一个会出现信息丢失、重复、乱序的底层通信媒介上,设计一组交互协议来可靠保序地传递信息,同时还要兼顾传输的性能和稳定性。上篇提到 TCP 是基于自动重复请求的机制(Automatic Repeat Request, ARQ)来设计的。简单说就是对待发送的数据(Payload)进行字节级别的编号(Sequence Number)。在 TCP 完成三次握手建立了连接后(在不携带数据的包里,握手的 SYN 包和挥手的 FIN 也要占用编号),发送的数据均带有相应的位置序号。接收端可以根据序号对数据进行重排序来解决传输过载中存在的乱序送达的情况,并回复 ACK 包给发送端以告知数据送达(不需要请求回复一对一,只需要 ACK 最大的位置即可)。基于这个朴素的数据编号的想法,TCP 完成了发送和接收数据的基本逻辑。