编译和链接那点事<下>
上回书我们说到了链接以前,今天我们来研究最后的链接问题。
链接这个话题延伸之后完全可以跑到九霄云外去,为了避免本文牵扯到过多的话题导致言之泛泛,我们先设定本文涉及的范围。我们今天讨论只链接进行的大致步骤及其规则、静态链接库与动态链接库的创建和使用这两大块的问题。至于可执行文件的加载、可执行文件的运行时储存器映像之类的内容我们暂时不讨论。
首先,什么是链接?我们引用CSAPP的定义:链接(linking)是将各种代码和数据部分收集起来并组合成为一个单一文件的过程,这个文件可被加载(或被拷贝)到存储器并执行。
需要强调的是,链接可以执行于编译时(compile time),也就是在源代码被翻译成机器代码时;也可以执行于加载时,也就是在程序被加载器(loader)加载到存储器并执行时;甚至执行于运行时(run time),由应用程序来执行。
说了这么多,了解链接有什么用呢?生命这么短暂,我们干嘛要去学习一些根本用不到的东西。当然有用了,继续引用CSAPP的说法,如下:
- 理解链接器将帮助你构造大型程序。
- 理解链接器将帮助你避免一些危险的编程错误。
- 理解链接将帮助你理解语言的作用域是如何实现的。
- 理解链接将帮助你理解其他重要的系统概念。
- 理解链接将使你能够利用共享库。
……
言归正传,我们开始吧。为了避免我们的描述过于枯燥,我们还是以C语言为例吧。想必大家通过我们在上篇中的描述,已经知道C代码编译后的目标文件了吧。目标文件最终要和标准库进行链接生成最后的可执行文件。那么,标准库和我们生成的目标文件是什么关系呢?
其实,任何一个程序,它的背后都有一套庞大的代码在支撑着它,以使得该程序能够正常运行。这套代码至少包括入口函数、以及其所依赖的函数构成的函数集合。当然,它还包含了各种标准库函数的实现。
这个“支撑模块”就叫做运行时库(Runtime Library)。而C语言的运行库,即被称为C运行时库(CRT)。
CRT大致包括:启动与退出相关的代码(包括入口函数及入口函数所依赖的其他函数)、标准库函数(ANSI C标准规定的函数实现)、I/O相关、堆的封装实现、语言特殊功能的实现以及调试相关。其中标准库函数的实现占据了主要地位。标准库函数大家想必很熟悉了,而我们平时常用的printf,scanf函数就是标准库函数的成员。C语言标准库在不同的平台上实现了不同的版本,我们只要依赖其接口定义,就能保证程序在不同平台上的一致行为。C语言标准库有24个,囊括标准输入输出、文件操作、字符串操作、数学函数以及日期等等内容。大家有兴趣的可以自行搜索。
既然C语言提供了标准库函数供我们使用,那么以什么形式提供呢?源代码吗?当然不是了。下面我们引入静态链接库的概念。我们几乎每一次写程序都难免去使用库函数,那么每一次去编译岂不是太麻烦了。干嘛不把标准库函数提前编译好,需要的时候直接链接呢?我很负责任的说,我们就是这么做的。
那么,标准库以什么形式存在呢?一个目标文件?我们知道,链接的最小单位就是一个个目标文件,如果我们只用到一个printf函数,就需要和整个库链接的话岂不是太浪费资源了么?但是,如果把库函数分别定义在彼此独立的代码文件里,这样编译出来的可是一大堆目标文件,有点混乱吧?所以,编辑器系统提供了一种机制,将所有的编译出来的目标文件打包成一个单独的文件,叫做静态库(static library)。当链接器和静态库链接的时候,链接器会从这个打包的文件中“解压缩”出需要的部分目标文件进行链接。这样就解决了资源浪费的问题。
Linux/Unix系统下ANSI C的库名叫做libc.a,另外数学函数单独在libm.a库里。静态库采用一种称为存档(archive)的特殊文件格式来保存。其实就是一个目标文件的集合,文件头描述了每个成员目标文件的位置和大小。
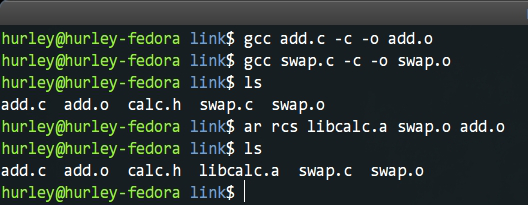
光说不练是假把式,我们自己做个静态库试试。为了简单起见我们就做一个只有两个函数的私有库吧。
我们在swap.c里定义一个swap函数,在add.c里定义了一个add函数。最后还有含有它们声明的calc.h头文件。
1 | // swap.c |
1 | // add.c |
1 | // calc.h |
我们分别编译它们得到了swap.o和add.o这两个目标文件,最后使用ar命令将其打包为一个静态库。
现在我们怎么使用这个静态库呢?我们写一个test.c使用这个库中的swap函数吧。代码如下:
1 |
|
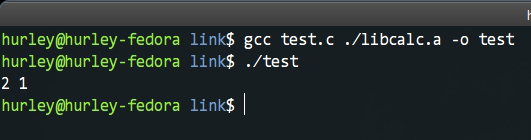
下来是编译执行,命令行执行gcc test.c ./libcalc.a -o test编译,执行。如图,我们输出了预期的结果。
可能你会问,我们使用C语言标准库的时候,编译并不需要加什么库名啊。是的,我们不需要。因为标准库已经是标准了,所以会被默认链接。不过因为数学函数库libm.a没有默认链接,所以我们使用了数学函数的代码在编译时需要在命令行指定 -lm 链接(-l是制定链接库,m是去掉lib之后的库名),不过现在好多gcc都默认链接libm.c库了,比如我机子上的gcc 4.6.3会默认链接的。
正如我们所看到的,静态链接库解决了一些问题,但是它同时带来了另一些问题。比如说每一个使用了相同的C标准函数的程序都需要和相关目标文件进行链接,浪费磁盘空间;当一个程序有多个副本执行时,相同的库代码部分被载入内存,浪费内存;当库代码更新之后,使用这些库的函数必须全部重新编译……
有更好的办法吗?当然有。我们接下来引入动态链接库/共享库(shared library)。
动态链接库/共享库是一个目标模块,在运行时可以加载到任意的存储器地址,并和一个正在运行的程序链接起来。这个过程就是动态链接(dynamic linking),是由一个叫做动态链接器(dynamic linker)的程序完成的。
Unix/Linux中共享库的后缀名通常是.so(微软那个估计大家很熟悉,就是DLL文件)。怎么建立一个动态链接库呢?
我们还是以上面的代码为例,我们先删除之前的静态库和目标文件。首先是建立动态链接库,我们执行gcc swap.c add.c -shared -o libcalc.so 就可以了,就这么简单(微软那个有所区别,我们在这里只为说明概念,有兴趣的同学请自行搜索)。
顺便说一下,最好在gcc命令行加上一句-fPIC让其生成与位置无关的代码(PIC),具体原因超出本文范围,故不予讨论。

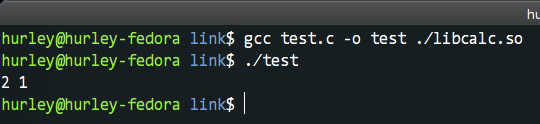
如何使用呢?我们继续编译测试代码,执行gcc test.c -o test ./libcalc.so即可。运行后我们仍旧得到了预期的结果。
这看起来也没啥不一样的啊。其实不然,我们用ldd命令(ldd是我们在上篇中推荐的GNU binutils工具包的组成之一)检查test文件的依赖。
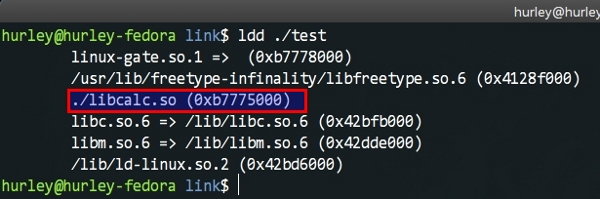
我们看到这个文件能顺利运行需要依赖libcalc.so这个动态库,我们还能看到C语言的标准库默认也是动态链接的(在gcc编译的命令行加上 -static 可以要求静态链接)。
好处在哪?第一,库更新之后,只需要替换掉动态库文件即可,无需编译所有依赖库的可执行文件。第二,程序有多个副本执行时,内存中只需要一份库代码,节省空间。
大家想想,C语言标准库好多程序都在用,但内存只有一份代码,这样节省的空间很可观吧,而且假如库代码发现bug,只需要更新libc.so即可,所有程序即可使用新的代码,岂不是很Cool。
好了,关于库我们就说到这里了,再说下去就没法子结束了。
我们来看看链接过程中具体做的事情。链接的步骤大致包括了地址和空间分配(Address and Storage Allocation)、符号决议(Symbol Resolution)和重定位(Relocation)等主要步骤。
首先是地址和空间分配,我们之前提到的目标文件其实全称叫做可重定位目标文件(这只是一种翻译,叫法很多…)。目标文件的格式已经无限度接近可执行文件了,Unix/Linux下的目标文件的格式叫做ELF(Executable and Linkable Format,可执行连接格式)。详细的讨论可执行文件的格式超出了本文范围,我们只需要知道可执行文件中代码,数据,符号等内容分别存储在不同的段中就可以了,这也和保护模式下的内存分段是有一定关系的,但是这个又会扯远就不详谈了……
地址和空间分配以及重定位我们简单叙述一下就好,但是符号决议这里我想稍微展开描述一下。
什么是符号(symbol)?简单说我们在代码中定义的函数和变量可以统称为符号。符号名(symbol name)就是函数名和变量名了。
目标文件的拼合其实也就是对目标文件之间相互的符号引用的一个修正。我们知道一个C语言代码文件只要所有的符号被声明过就可以通过编译了,可是对某符号的引用怎么知道位置呢?比如我们调用了printf函数,编译时留下了要填入的函数地址,那么printf函数的实际地址在那呢?这个空位什么时候修正呢?当然是链接的时候,重定位那一步就是做这个的。但是在修改地址之前需要做符号决议,那什么是符号决议呢?正如前文所说,编译期间留下了很多需要重新定位的符号,所以目标文件中会有一块区域专门保存符号表。那链接器如何知道具体位置呢?其实链接器不知道,所以链接器会搜索全部的待链接的目标文件,寻找这个符号的位置,然后修正每一个符号的地址。
这时候我们可以隆重介绍一个几乎所有人在编译程序的时候会遇见的问题——符号查找问题。这个通常有两种错误形式,即找不到某符号或者符号重定义。
首先是找不到符号,比如,当我们声明了一个swap函数却没有定义它的时候,我们调用这个函数的代码可以通过编译,但是在链接期间却会遇到错误。形如“test.c:(.text+0x29): undefined reference to ‘swap’”这样,特别的,MSVC编译器报错是找不到符号_swap。咦?那个下划线哪里来的?这得从C语言刚诞生说起。当C语言刚面世的时候,已经存在不少用汇编语言写好的库了,因为链接器的符号唯一规则,假如该库中存在main函数,我们就不能在C代码中出现main函数了,因为会遭遇符号重定义错误,倘若放弃这些库又是一大损失。所以当时的编译器会对代码中的符号进行修饰(name decoration),C语言的代码会在符号前加下划线,fortran语言在符号前后都加下划线,这样各个目标文件就不会同名了,就解决了符号冲突的问题。随着时间的流逝,操作系统和编译器都被重写了好多遍了,当前的这个问题已经可以无视了。所以新版的gcc一般不会再加下划线做符号修饰了(也可以在编译的命令行加上-fleading-underscore/-fno-fleading-underscore开打开/关闭这个是否加下划线)。而MSVC依旧保留了这个传统,所以我们可以看到_swap这样的修饰。
顺便说一下,符号冲突是很常见的事情,特别是在大型项目的开发中,所以我们需要一个约定良好的命名规则。C++也引入了命名空间来帮助我们解决这些问题,因为C++中存在函数重载这些东西,所以C++的符号修饰更加复杂难懂(Linux下有c++filt命令帮助我们翻译一个被C++编译器修饰过的符号)。
说了这么多,该到了我们变成中需要注意的一个大问题了。即存在同名符号时链接器如何处理。不是刚刚说了会报告重名错误吗?怎么又要研究这个?很可惜,不仅仅这么简单。在编译时,编译器会向汇编器输出每个全局符号,分为强(strong)符号和弱符号(weak),汇编器把这个信息隐含的编码在可重定位目标文件的符号表里。其中函数和已初始化过的全局变量是强符号,未初始化的全局变量是弱符号。根据强弱符号的定义,GNU链接器采用的规则如下:
- 不允许多个强符号
- 如果有一个强符号和一个或多个弱符号,则选择强符号
- 如果有多个弱符号,则随机选择一个
好了,就三条,第一条会报符号重名错误的,而后两条默认情况下甚至连警告都不会有。关键就在这里,默认甚至连警告都没有。
我们来个实验具体说一下:
1 | // link1.c |
1 | // link2.c |
这两个文件编译运行会输出什么呢?聪明的你想必已经知道了吧?没错,就是5。
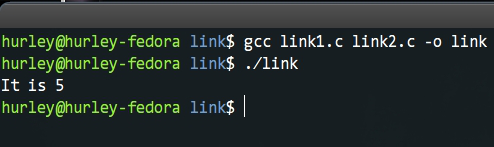
初始化过的n是强符号,被优先选择了。但是,在很复杂的项目代码,这样的错误很难发现,特别是多线程的……不过当我们怀疑代码中的bug可能是因为此原因引起的时候,我们可以在gcc命令行加上-fno-common这个参数,这样链接器在遇到多重定义的符号时,都会给出一条警告信息,而无关强弱符号。如图所示:
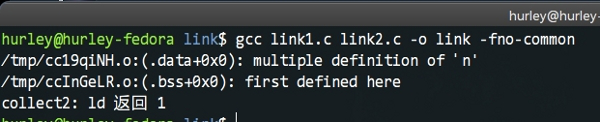
好了,到这里我们的下篇到此也该结束了,不过关于编译链接其实远比这深奥复杂的多,我权当抛砖引玉,各位看官自可深入研究。
P.S. 并非我刻意更新慢,只是一篇博文确实需要很多考证和资料收集,把博文当成论文写本身就很麻烦的,需要各种实验和考证。帮人事小,误人事大。各位看官发现问题尽管批评,哪怕是错别字,多谢。

