保护模式汇编系列之四 - 段页式内存管理(二)
我们这次接着内存分页继续说。稍微插一句,虽然本系列的名字叫做保护模式汇编,可是到现在颇有些挂羊头卖狗肉的意味。我们只是在一个劲的谈理论,就连仅有的一点代码也是用C语言描述的,而不是汇编。不过我觉得这不是关键,我觉得只要我们掌握了理论就好,至于用什么语言描述都是次要的,你说呢?
言归正传,我们开始说分页机制。长时间以来,随着计算机技术的发展,存储器的容量在不断的高速增加着。但是说起内存(这里指RAM,下同)这个东西,它有一个很奇葩的特性,就是无论它有多大,都总是不够用(P.S.厨房的垃圾桶也一样)。现在我们看似拥有着以前的程序员想都不敢想的“天文数字”的内存,动辄就是几G十几G的。但是相信我,历史总是嘲弄人的。就像当年程序员们质疑32位地址线带来的4GB空间太大没有意义似的,我们也会有一天抱怨现在的内存太小的。
那么,既然内存总是不够用的,那内存不够用了怎么办?还有,使用过程中出现的内存碎片怎么办?假设我们有4GB的物理内存,现在有1、2、3、4一共4个程序分别各占据连续的1G内存,然后2、4退出,此时我们拥有着空闲的两段内存,却连一个稍大于1GB的程序都无法载入了。
当然了,这只是一个例子。不过按照一般的思路,在内存释放之后,我们如何回收呢?做碎片整理吗?即便我们不在乎整理过程带来的效率损失,光是程序加载时候的地址逐一重定位就是及其麻烦的。那怎么办?当然了,解决的办法是有的,聪明的计算机工程师们想到了采用分页的方式来管理物理内存。他们在逻辑上把内存划分为定长的物理页,同时将一个程序执行时候的线性地址地址空间划分为逻辑页,在分页机制工作的前提下,给硬件提供一组数据结构来保存这种映射关系。也就是说,线性地址是连续的,但是其实际指向的物理地址就不见得是连续的了。别忘了,RAM是随机存储器,读取任意一个地址的理论时间都是一样的(暂时让我们忘了cache吧…)。我们让CPU在寻址的时候,自动的去查找线性地址到物理地址的映射关系,从而找到实际的数据就好。严格说地址翻译是由MMU组件来进行的,但是现在MMU一般都是CPU的一个组成部分了,所以我们也不严格区分了。
是不是文字读的有点混乱?我们来张图看看(网上找不到顺心的,用WPS表格画了一张,顺便推荐WPS for Linux,真心不错)。
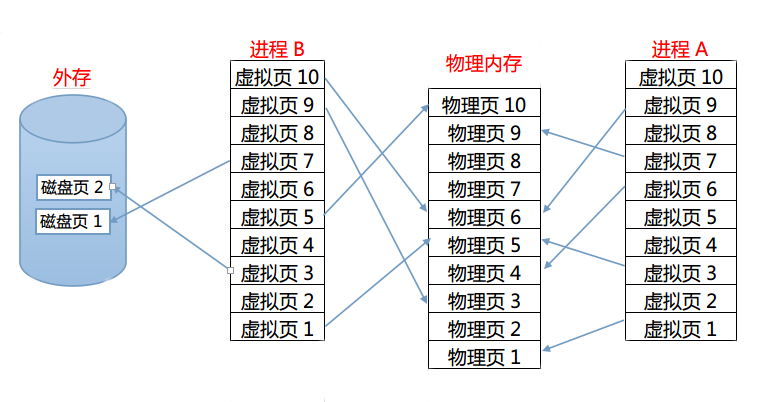
一图胜千言,我们看到了固定大小的物理页、虚拟页、甚至还有磁盘页。我觉得这张图片很能说明问题了,我相信聪明的你从这里都悟出来了虚拟内存的实现原理了。没错,虚拟内存实质上就是把物理内存中暂时用不到的内容暂时换出到外存里,空出内存放置现阶段需要的数据。至于替换的策略当然有相应的算法了,比如最先换入原则,最少使用原则等等方法可以使用。
相信通过上文的描述,我们对分页已经建立了初步的理解了。那么接下来的问题是,怎么表示和存储这个映射关系。这里描述起来简单,但是代码就不是那么直观了,原因很简单,因为我们需要一组数据结构来管理内存,但是这组数据结构本身也得放在内存里。所以牵扯到一个自己管理自己的问题。而且,开启分页模式之后,CPU立即就会按照分页模式的规则去解释线性地址了。所以,这意味着我们必须先建立好地址映射的数据结构,才能开启分页,而且我们必须保证之前的代码地址和数据地址都能映射正确。
其实这篇我是不准备贴实际的代码的,因为怕把大家绕晕了。本篇虽然一直都是围绕着x86在说,但是截至目前我们的描述都是不针对某一个具体CPU而言的,所以上述概念是通用的。
下面我们来说说x86下的一种简单的做法吧。我们以32位为例。为什么不是64位?一是因为复杂;二呢?我暂时还不懂64位…哈哈。
在32位操作系统下我们使用32位地址总线(暂时原谅我在这里错误的描述吧,其实还有PAE这个东西),所以我们的寻址空间有2^32,也就是4GB。一定要注意,我们强调了很多次了,这个空间里,有一些断断续续的地址实际上是指向了其它的外设,不过大部分还是指向RAM的。我们采取的分页大小可以有多种选择,但是过于小的分页会造成管理结构太大,过于大的分页又浪费内存。现在较为常见的分页是4KB一个页,也就是4096字节一个页。我们简单计算下,4GB的内存分成4KB一个的页,那就是1MB个页,没错吧?每个虚拟页到物理页的映射需要4个字节来存储的话(别忘了前提是32位环境下),整个4GB空间的映射需要4MB的数据结构来存储。
目前看起来一切都很好,4MB似乎也不是很大。但是,这只是一个虚拟地址空间的映射啊,别忘了每个进程都有自己的映射,而且操作系统中通常有N个进程在运行。这样的话,假如有100个进程在运行,就需要400MB的内存来存储管理信息!这…太浪费了…
怎么办?聪明的工程师们提出了分级页表的实现策略,他们提出了页目录,页表的概念。以32位的地址来说,分为3段来寻址,分别是地址的低12位,中间10位和高10位。高10位表示当前地址项在页目录中的偏移,最终偏移处指向对应的页表,中间10位是当前地址在该页表中的偏移,我们按照这个偏移就能查出来最终指向的物理页了,最低的12位表示当前地址在该物理页中的偏移。就这样,我们就实现了分级页表。我们来张图看看:
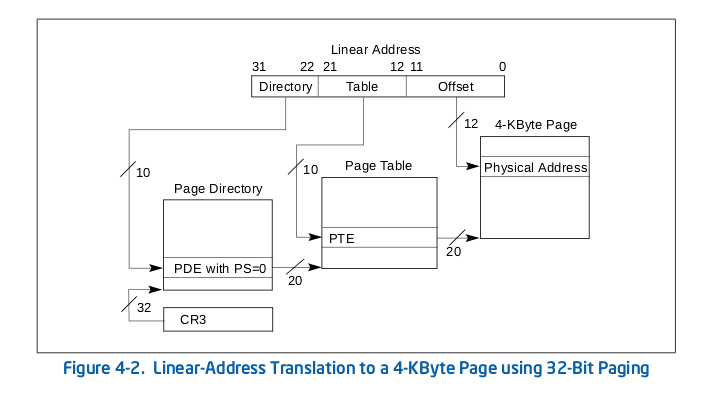
也许你已经算出来了,这样做的话映射4GB地址空间需要4MB+4KB的内存。我们这是搬起石头砸了自己的脚吗?当然不是,因为在一个进程中,实际使用到的内存大都远没有4GB这么大,所以通过两级页表的映射,我们就可以只映射需要的地址就可以了,是不是节省了内存呢?概念我们暂时就说到这里,更专业的描述和规范请参阅Intel文档,也就是上面那个图的出处。
好了,也许这是本系列最后一篇了。可能你会说保护模式的东西还多着啊,这才哪到哪啊。没错,这仅仅是保护模式的冰山一脚。结束本系列的原因是有新的系列要开始了,而且我觉得这个新的系列听起来更酷更有意思,也更有实践性。什么系列呢?这个系列我们讨论自己写一个小的“操作系统”。怎么样,听起来是不是很酷很好玩?话是这么说没错,但是我们所谓的“操作系统”可能仅仅只是一个Demo,一个x86硬件原理演示性质的东西罢了。但是,它却能帮助我们理解和掌握更多深层次的东西。我们不仅仅满足虚拟机上自娱自乐,最后我们还要让它跑在物理机器上来展示最终的效果。
你是不是已经迫不及待了呢?别着急,容我整理下思路先…
不会太久的,敬请期待。

