聊聊内存管理
这篇文章我们聊聊内存管理。
本来我想不针对于任何具体的操作系统来谈内存管理,但是又觉得不接地气、言之无物。所以我决定在阐述概念的同时,还针对 x86 Linux 下的内存管理做简要的介绍,并且以实验来证明结论。以下内容分拆为几个大标题和小节,内容前后承接。
物理地址空间
首先,什么是物理地址空间?我们知道 CPU 与外部进行信息传递的公用通道就是总线,一般而言,CPU 有三大总线:控制总线、数据总线、地址总线。这三类总线在一定程度上决定了 CPU 对外部设备的控制和数据传送能力。其中地址总线决定了 CPU 能向外部输出的地址宽度,也就是 CPU 的寻址能力。
通过 /proc/cpuinfo 可以查看具体的数据:
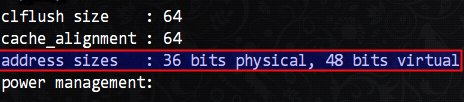
本文只需要关心红色框内的信息即可,我的CPU拥有36位地址总线,其寻址范围是 2^36=64G. 那么其物理上理论能编址的上限就是这么大了。这里显示虚拟地址 48 bits,我们知道 64 bits 的操作系统下地址是 64 bits 的(64位的指针),但是目前的 x86_64 在所有的 CPU 型号上用的都是 48 bits 的虚拟地址,也就是说地址的前 17 位都只是一样,以位扩展的方式工作(也就是说 64 - 48 = 16 的这 16 bits 是冗余的)。但是物理上呢?实际上 CPU 只有 46 bits 的物理地址线宽度,因为现在目前的这些 CPU 型号在过时之前,不可能真的用到那么大的地址范围,没必要浪费。关于48 bits virtual 以及 64 bit 的现有实现,则可以参考这里。
《Intel® 64 and IA-32 Architectures Software Developer’ s Manual》对物理地址空间的解释如下:

重点标记的区域请认真阅读,物理地址空间一定就是内存(DRAM)么?显然不是,文档里也指出了物理地址空间可以映射到 read-write memory、read-only memory和memory mapped I/O.
也就是说,除了常见的内存(DRAM),还有主板上的 ROM 和 EEPROM(BIOS、显存等等)也在这个地址空间里。常见的编址方案有IO独立编址和IO统一编址,具体的讨论可以参考这里。下面就假定读者接受了这一基本事实。
启动时的内存信息获取
BIOS 的中断调用
上一节说到,物理地址空间被映射到了主存储器,主板上芯片的存储区域等位置。那么,操作系统如何得知这一映射关系,显然不同品牌的机器和主板不可能完全一致么。答案就在 BIOS(Basic Input/Output System) 了,那 BIOS 又如何得知呢?嗯,那就是—探测。具体说来,BIOS 其实是一个通称,显卡、网卡、键盘接口电路等外设上都会有一块 ROM 芯片用于其初始化检测和功能调用。按照规范,这个部分前两个字节必须是0x55和0xAA(和可启动存储介质的第一个扇区结尾字符一样,注意区别),第三个字节是其 ROM 以512为单位的代码长度,之后就是代码了。从物理地址 A0000~FFFFF 之间的区域就是保留给外围设备的,如果外设存在,其自带的ROM就会被映射到这个区域。主板 BIOS 在机器加电后,会以2KB为单位在 C0000~E0000 之间检索 0x55 和 0xAA 并校验长度,执行 ROM 的代码。有兴趣你可以去读《BIOS研发技术剖析》类似的书,这里我个人不怎么了解,就不敢再多说了。
啰嗦了这么多,其实只需要明白最初的地址映射表是由BIOS检测并提供给操作系统的就好。而操作系统获取这个表的方法自然就是BIOS的中断调用了。e820调用即可获取这些信息,终端下使用dmesg命令打印内核日志就可以看到内核打印出的物理内存布局了。
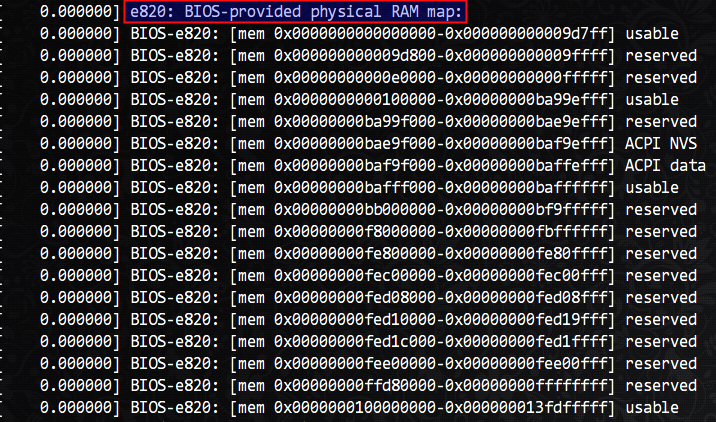
简要解释下上面的输出:
Usable:是已经被映射到物理内存(DRAM)的物理地址。
Reserved:这些区间是没有被映射到任何地方,不能当作内存来使用。(内核可以修改这些映射,
/proc/iomem文件描述了具体的映射)ACPI data:映射到用来存放 ACPI 数据的 RAM 空间,ACPI Table 应读入到这个区间内。
ACPI NVS:映射到存放 ACPI 数据的空间,操作系统不能使用。
至于具体的 e820 调用怎么用,就不展开说了。这段之后的信息有兴趣的同学可以接着去读,内核对内存的映射和统计信息也会随后打印出来。
Shadow RAM
这个小节其实是次要的,留在这里只是为了完整性,本文也不展开去描述了。还是那句话,有探究兴趣的话,请自行去 Google.
物理内存管理
通过前文的描述,我想大家已经知道了操作系统终归是拿到了一张物理地址空间的映射表了。那么所谓的内存管理,最主要的部分就是如何来管理主存也就是 DRAM 的空间了。此处主要的挑战就是实现具体的数据结构和算法,使得内存分配的时候高效的分配内存,并且在内存释放时进行相邻内存块的合并回收以避免内存外部碎片的产生。
Linux 内核采用的伙伴内存分配算法就是用来解决这一问题的。 关于 Linux 的内存管理有无数的好文章和好书在描述了,本文的定位就是梳理脉络,所以我只给出链接,请大家自行去了解。
伙伴算法的实现自然不只有一种思路,看看下面的文章也是一种启发:
虚拟内存管理
接下来就是虚拟内存管理了,[保护模式汇编系列之四] 段页式内存管理,请先看看我以前写得这篇文章了解下虚拟内存出现的原因和解决的问题。我不想太纠结于细节,以免这篇文章过于冗长,但是有些细节不交代清楚有没有办法继续下去。只有自己真正理解掌握了所有细节,才敢站在较高的层次上俯视整个知识脉络,这里的Linux虚拟内存管理容我自己理解深入之后再行补充。
大家可以先参考下武特学长的博文,然后就可以进到下一个章节。
Linux 进程的内存布局
又要偷懒贴文章了,之前有写过一篇《进程眼中的线性地址空间》,这里描述的即是虚拟地址空间里的4G线性地址的映射:
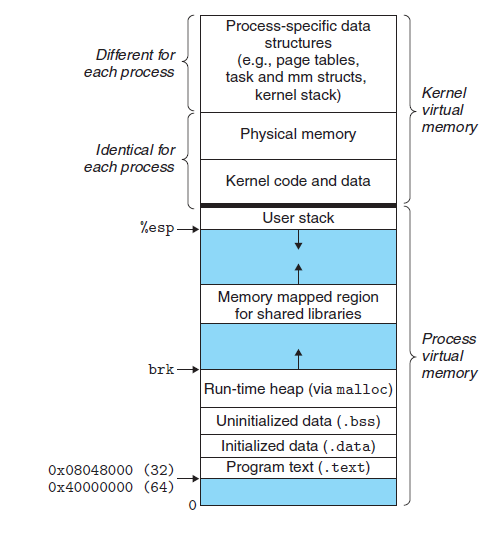
学过操作系统的同学一定知道PCB(Process Control Block,进程控制块)吧。
用课本上的话说,进程控制块是用来描述进程的当前状态,本身特性的数据结构,是进程中组成的最关键部分,其中含有描述进程信息和控制信息,是进程的集中特性反映,是操作系统对进程具体进行识别和控制的依据。
具体到Linux内核中,所谓的PCB其实就是task_struct这个结构体了。既然PCB描述了进程的信息,自然也就包括了进程内存空间的相关描述信息了。内存相关信息在struct mm_struct *mm, *active_mm字段,mm指向进程所拥有的内存描述符,而 active_mm 指向进程运行时所使用的内存描述符。mm_struct里的pgd_t * pgd字段即指向进程的页目录。struct vm_area_struct *mmap字段指向虚拟区间(VMA)链表。如下图所示:
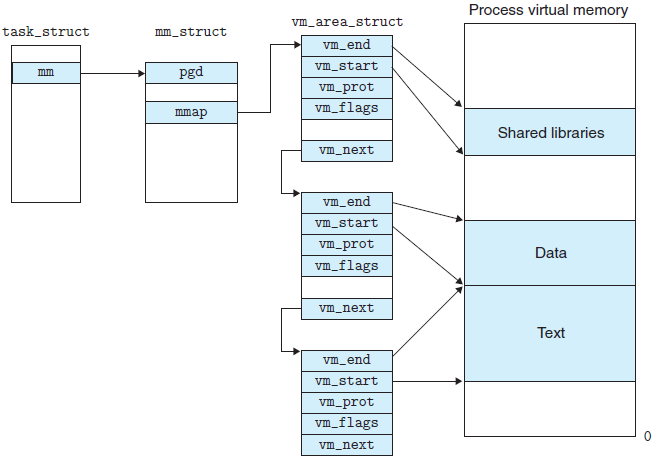
了解了这些,就可以到本文的最后一部分了。
探究 malloc 的效率与写时映射
开始描述前,写点代码玩玩先。通过上文的描述,我想大家已经了解了 32bit 下 Linux 进程拥有的 4G 线性地址空间只有 3G 是属于进程所有的。那么我们容易想到,malloc函数从堆里获取到的内存最多也不会超出这个范畴。而程序代码和链接库部分也占据了一定的空间,所以可以申请到的内存的总数应该略与 3G 这个数字(视进程本身代码和数据占据大小而定)。代码如下:
1 |
|
编译运行,结果如下:

这基本也证实了我们的猜想。接着我们去掉sleep语句用time命令记录内存申请时间可以看到:
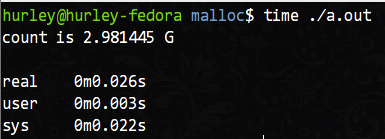
以 1MB 为单位分配接近 3G 的内存也太快了点吧,就是逐一建立页表也没有这般迅速吧?
更神奇的还在后面,如果我们让程序sleep,在另一个终端执行free命令查看内存占用的话,会看到神奇的结果:

used那里居然几乎没有增加,这不科学!
Linux 系统调用提供的内存获取的函数是brk/sbrk和mmap,而且时以页(通常4K)为单位进行内存的分配的。而Glibc实现的malloc/free是建立在系统调用之上的内存“批发后零售”的函数。问题肯定出在brk/sbrk等系统调用上。这两个系统调用是增加程序可用的堆区的空间,其实内核仅仅只是修改里进程PCB里vm_area_struct链表中堆那个节点的结束位置(许可地址范围),并没有真正去获取物理内存并建立页表的映射。为什么要这么做呢?原因大家可以自己去思考,比如进程申请的内存不一定立即就会完全用到,可以延迟到使用的时候再去分配,以暂时节省物理内存。那么具体流程是怎样的呢?
其实,CPU 在分页开启后,对于给出的线性地址(此处略过分段)会由MMU进行页表的查阅来翻译为最终的物理地址,如果在页表中查阅不到或者该页不存在呢?此时 CPU 会产生一个内部异常: 14 #PF 页故障。此时处理流程会转入到内核为该异常创建的对应异常处理函数去执行,内核此处的代码首先会遍历当前进程的vm_area_struct链表,检查该地址是否在许可的地址范围内,如果是为其申请物理内存并建立映射。之后异常返回到触发了异常的代码出继续执行,所以程序接着运行下去。如果发现该地址是非法的地址,内核为给进程发信号SIGSEGV,该信号的默认处理函数即会打印出段错误,然后结束进程。流程即是:
缺页异常->异常处理函数->task_struct、mm_struct、vm_area_struct->页分配->中断返回
具体的函数调用细节,大家可以看看 malloc()之后,内核发生了什么?
这篇定位为科普的文章到此就结束了。几个小时仓卒写出来的初稿,先贴出来大家看看,后续再慢慢修改。

