浅谈服务端编程
我们假定读者掌握了:
- Linux环境下C/C++的系统编程和基本的socket编程方法
- 操作系统基本概念以及Linux的基本概念和原理
- Linux进程和线程的内存地址空间布局和资源关系
我们谈什么,不谈什么:
- Linux下的网络程序设计所遵循的规范
- Linux网络程序的工作模型和原理
- 一般性质上的网络协议设计方法和原则
- 基本上只针对Linux,基本不涉及Windows
- 只涉及TCP协议的通信,不谈UDP
可以先行阅读的参考资料:
进程眼中的线性地址空间
线程眼中的线性地址空间
Linux线程的前世今生
聊聊内存管理
Linux系统调用
goroutine背后的系统知识
从基本socket函数开始
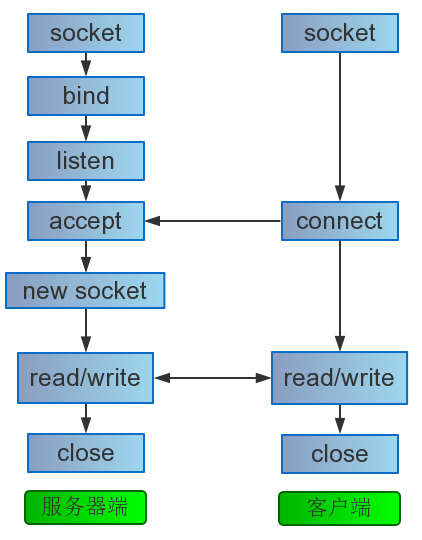
留意一些socket函数与众不同的参数细节
1 | int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen); |
TCP三次握手在socket接口的位置
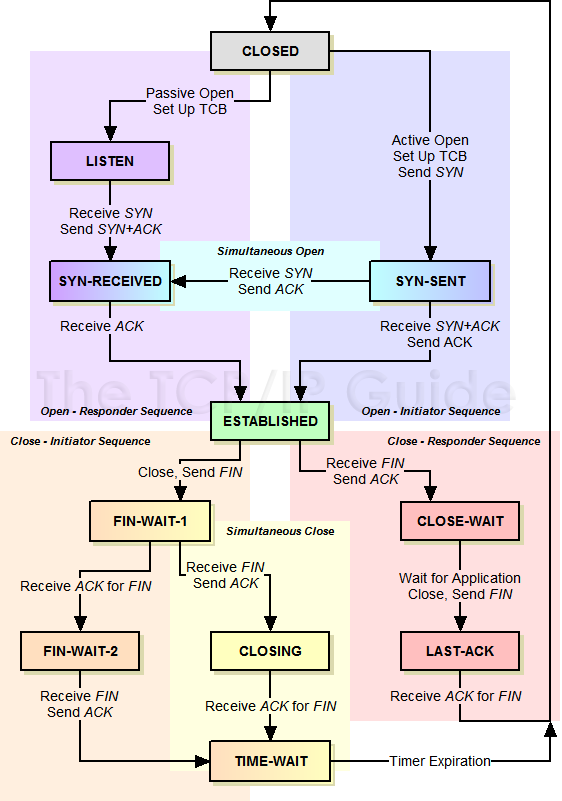
强调TIME_WAIT状态
MSL(最大分段生存期)指明TCP报文在Internet上最长生存时间,每个具体的TCP实现都必须选择一个确定的MSL值。RFC1122建议是2分钟。
TIME_WAIT 状态最大保持时间是2 * MSL,也就是1-4分钟。
1 | int listen(int sockfd, int backlog); |
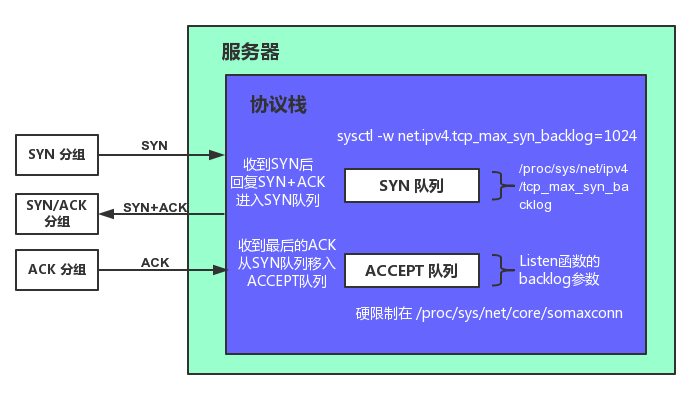
Linux内核协议栈
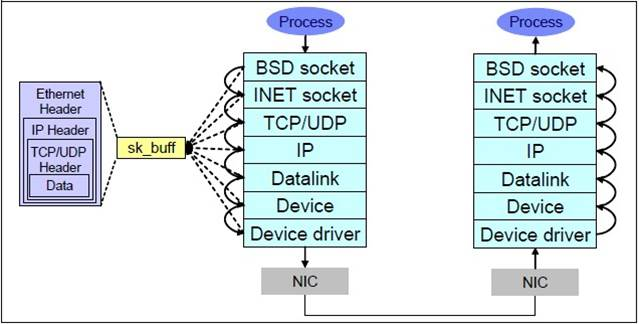
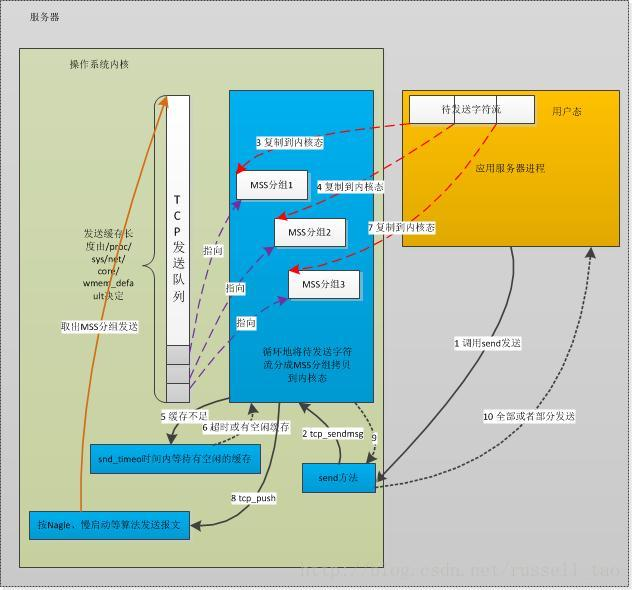
TCP 的发送
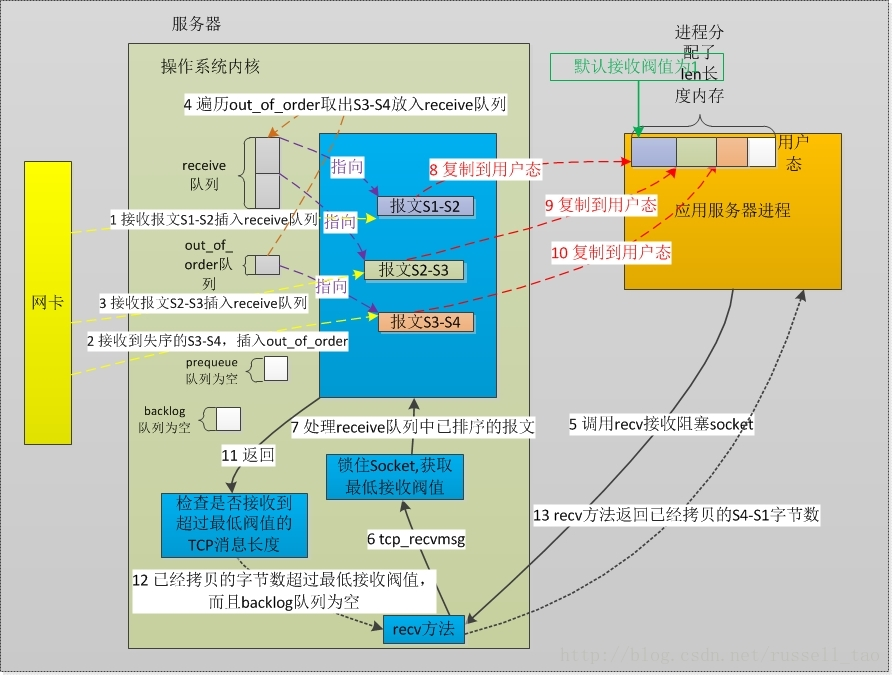
TCP的接收
协议栈完整的收发流程
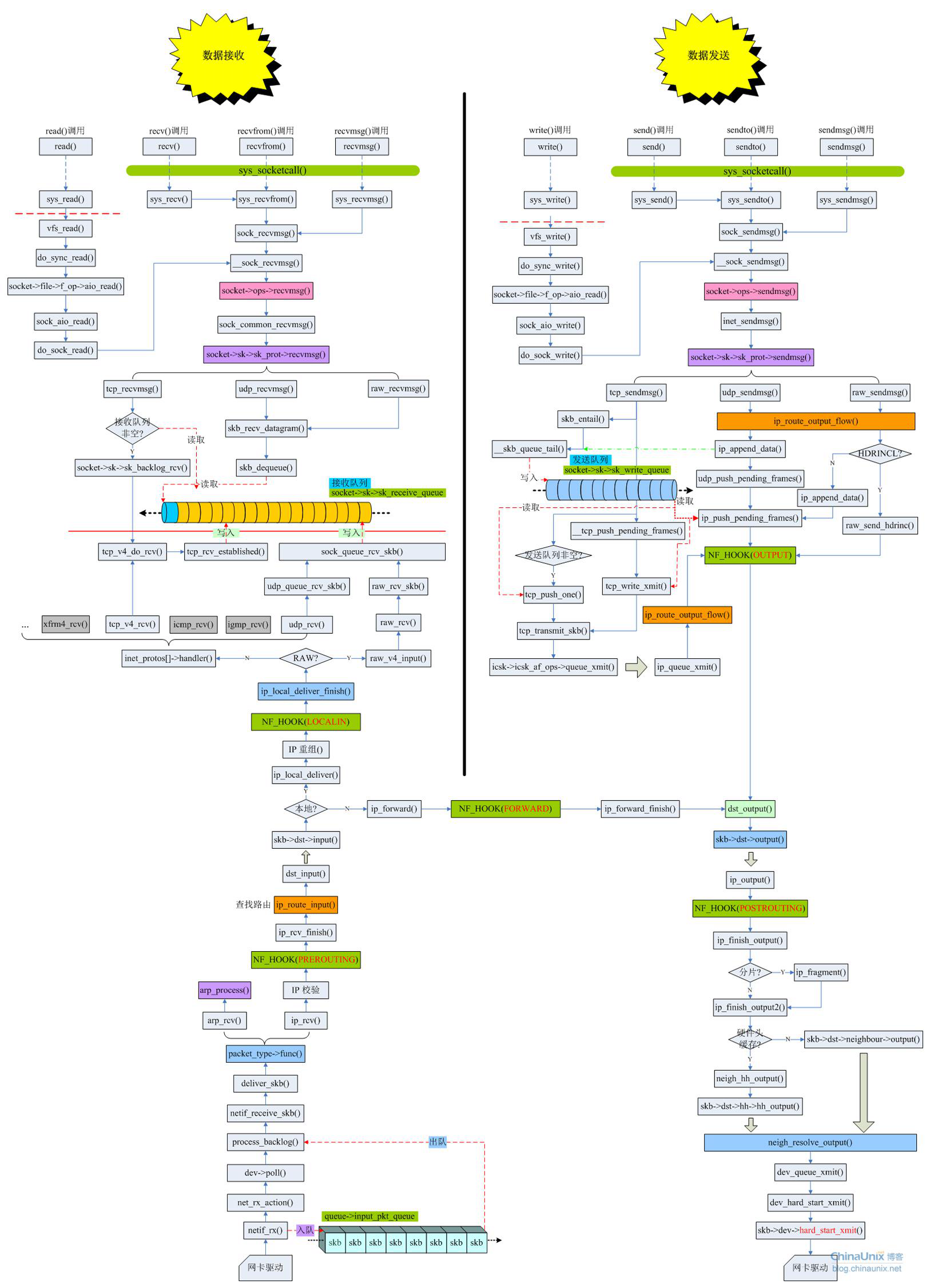
关于socket接口与内核协议栈的挂接
TCP相关参数的设置方法
套接字设置
1 |
|
SO_REUSEADDR
当有一个有相同本地地址和端口的socket1处于TIME_WAIT状态时,而你启动的程序的socket2要占用该地址和端口,你的程序就要用到该选项。这个选项允许同一port上启动同一服务器的多个实例(多个进程)。但每个实例绑定的IP地址是不能相同的。(多块网卡的应用场合)
SO_RECVBUF / SO_SNDBUF
发送和接收缓冲区大小,不详述。
TCP_NODELAY / TCP_CHORK
是否采用Nagle算法把较小的包组装为更大的帧。HTTP服务器经常使用TCP_NODELAY关闭该算法。相关的还有TCP_CORK。
TCP_DEFER_ACCEPT
推迟accept,实际上是当接收到第一个数据之后,才会创建连接。(对于像HTTP等非交互式的服务器,这个很有意义,可以用来防御空连接攻击。)
TCP_KEEPCNT / TCP_KEEPIDLE / TCP_KEEPINTVL
如果一方已经关闭或异常终止连接,而另一方却不知道,我们将这样的TCP连接称为半打开的。TCP通过保活定时器(KeepAlive)来检测半打开连接。设置SO_KEEPALIVE选项来开启KEEPALIVE,然后通过TCP_KEEPIDLE、TCP_KEEPINTVL和TCP_KEEPCNT设置keepalive的开始时间、间隔、次数等参数。
保活时间:keepalive_time = TCP_KEEPIDLE + TCP_KEEPINTVL * TCP_KEEPCNT
从TCP_KEEPIDLE 时间开始,向对端发送一个探测信息,然后每过TCP_KEEPINTVL 发送一次探测信息。如果在保活时间内,就算检测不到对端了,仍然保持连接。超过这个保活时间,如果检测不到对端,服务器就会断开连接,如果能够检测到对方,那么连接一直持续。
内核全局设置
内核的TCP/IP调优参数都位于/proc/sys/net/目录,可以直接写入数值或者采用sysctl命令或者系统调用。
1 |
|
详细请参考:提高 Linux 上 socket 性能
常见的协议格式设计
记住,TCP是一种流协议
语出《Effective TCP/IP Programming》。意思是,TCP的数据是以字节流的方式由发送者传递给接收者,没有固有的“报文”或者“报文边界”的概念。简单说,TCP不理解应用层通信的协议,不知道应用层协议格式和边界。所以,所谓的“粘包和断包”是个伪概念。TCP压根就没有包边界的概念,何谈粘与断。

OSI模型定义的7层结构网络中,TCP协议所在的传输层和应用层之间还有会话层和表示层,原本协议包分界和加密等等操作是在这两层完成的。TCP/IP协议在设计的时候,并没有会话层和表示层。那如果用户需要这两层提供的服务怎么办?比如包的分界?答案是,用户自行在应用层代码中实现吧。
示例:
发送者发送三次
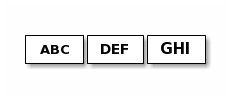
接收者可能收到这样:
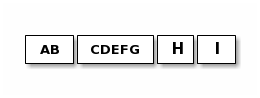
避免分片的效率损失
数据链路层Maximum Transmission Unit(MTU, 最大传输单元)。
以太网通常在1500字节上下。所以单次发送的协议包数据最好小于这个值,从而避免IP层分片带来的效率损失。
扩展阅读:Linux TCP/IP协议栈关于IP分片重组的实现
常见的协议格式
这个很简单,和文件一样,无非是纯文本格式或者二进制格式。
便于解包的协议设计方法
一般而言,应用层协议设计有四种常见方法:
- 每个发送的包长度固定
- 包每行均采取特殊结束标记用以区分(例如HTTP使用的\r\n)
- 包前添加长度信息(所谓的TLV模式,即type、length、value)
- 利用包本身的格式解析(如XML、JSON等)
以上1和3通常是二进制格式,2和4是文本格式。
有没有通用的二进制通信协议?推荐谷歌的ProtoBuf或者Apache Swift.
Need a demo?
#### 包长度固定很简单的思路,我们可以定义服务端和客户端均采用同一个结构体进行数据传输,这样的话很容易根据结构体大小来进行分隔收到的数据。这个不用写吧…
#### 包每行均采取特殊结束标记用以区分这个也很简单理解,采用纯ASCII发送信息的时候,完全可以采用这种方式。比如一个包中,每行采用\r\n进行分隔,包结束采用\r\n\r\n进行分隔等等。
如果在包的数据中出现了结束标记怎么办?转义呗~
这个理解起来也不困难,以结构体为例,即便是服务端和客户端采用多种结构体进行通信,只需要加上一个类型字段和长度字段,这样不就解决了么。
不过这里的type、length以及value只是指导思想,大家完全可以自行去实现自己的格式。
不要觉得这个貌似很搓的样子,看看QQ早些时候的定义:
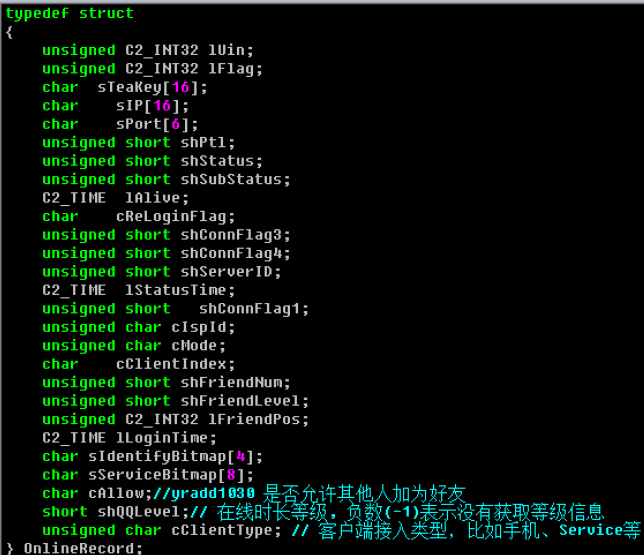
沈昭萌学长博客:TLV-简单的数据传输协议
1 | // 包类型 |
rio_readn 函数的实现如下
1 | size_t rio_readn(int fd, void *usrbuf, size_t n) |
analyse_protocol 是解析函数,简单的实现如下:
1 | // 协议解析程序 |
利用包本身的格式解析(如XML、JSON等)
这种方式也不难,我们可以通过Xml,Json本身的格式来匹配每一个具体的包。下面给出一个简单的XML接收和解析的简单例子和Qt下使用QtXml的解析方法。
上面是同步的,下面来个异步的:
1 | void MainWindow::clientDataReceived() |
常见的通信模型
研究server模型的目的
适应特定的硬件体系与OS特点
比如说相同的server模型在SMP体系下与NUMA下的表现就可能不尽相同,又如在linux下表现尚可的进程模型在windows下面就非常吃力。好的server 模型应该从硬件和OS的进步发展中,得到最大化的好处。
实现维护成本与性能的平衡
好的模型会在编程难度与性能之间做比较好的平衡,并且会很容易地在特定场景下做重心偏移。
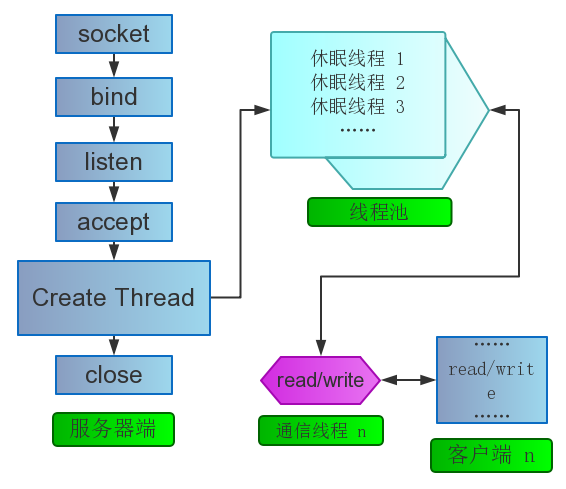
基本模型
多进程模型与原理
Unix/Linux特有模型,不必多说,可参考**子进程自父进程继承什么或未继承什么。**
最典型的应用当数传统CGI了。什么语言能写CGI?只要写出来的东东能运行,就能当CGI。c/c++、php、python、perl、甚至shell等等。
优化下就是prefork模型,传说中的进程池。
进程数的经验值可以这样估计: n=current * delay
Current 是并发量,delay 是平均任务时延。
当delay 为2,并发量current 为100 时,进程数至少要为200。
缺点:用进程数来抗并发用户数,因一台机器可启动的进程数是有限的,还没见到过进程能开到K级别,并且当进程太多时OS调度和切换开销往往也大于业务本身了。
多线程模型与原理
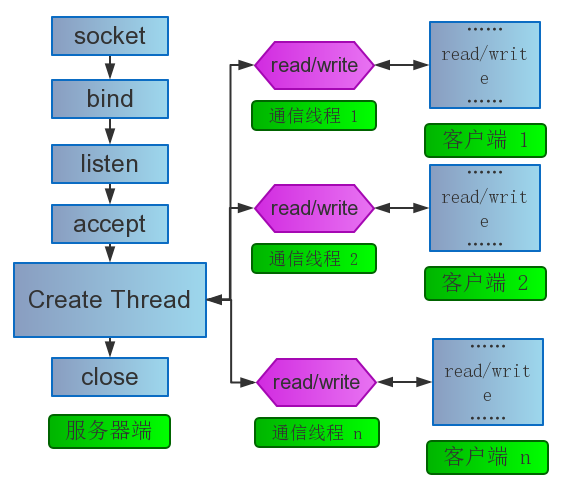
也不必多说了吧?对其进行简单的优化就是线程池模型了。
上面代码看看思想就好,99.99%的可能会有bug。
你会发现,C写的线程池把互斥锁、条件变量、队列和代码逻辑混合在一起很难理解。我们引入C++和RAII技术:RAII就是资源获取即初始化。简单说就是由相关的类来拥有和处理资源,在构造函数里进行资源的获取,在析构函数里对资源进行释放。由语言天生的作用域来控制资源,极大的解放了生产力和程序员思想包袱。
pthread_mutex的 例子
怎么用?戳这里的 无界阻塞队列
封装之后的代码:线程池
从同步到异步
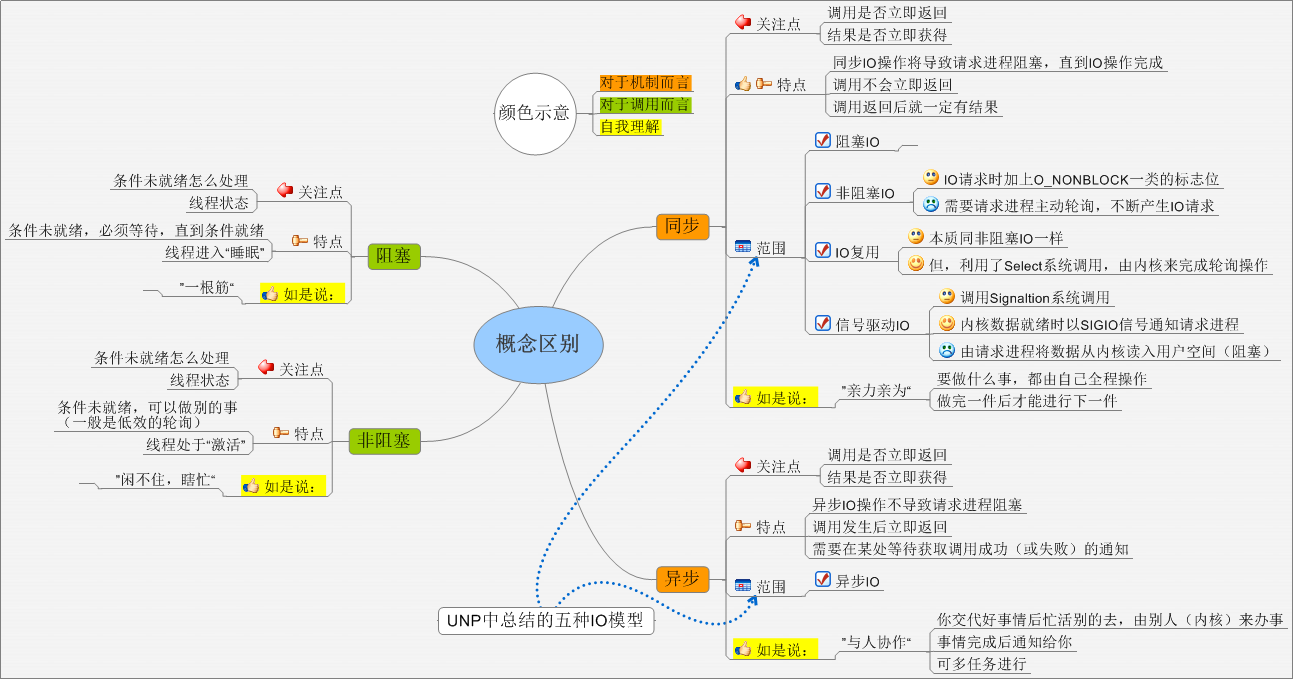
阻塞、非阻塞、同步、异步
非阻塞+IO复用
推荐方式,非阻塞必然和IO复用联合起来~(不然你要一直在用户态做轮询吗?)
这是异步IO?
啥是异步IO?看POSIX.1对同步I/O和异步I/O的定义:
- 同步I/O操作导致发出请求的进程被阻塞直到I/O操作完成。
- 异步I/O操作在I/O操作期间不导致发出请求的进程被阻塞。
根据这个定义,阻塞,非阻塞,多路复用,信号驱动均属于同步I/O(尽管信号驱动由于习惯原因,在以前被成为异步I/O)
Linux目前实现的两套异步IO方法
Pthread实现的AIO和Linxu内核实现的Native AIO。
缺点?Pthread的是在用线程模拟!完全不可用!内核的倒是异步,但是目前的实现没法利用IO缓存!不过在一些场合还是不错的。
可以参考:Linux AIO(异步IO)那点事儿
好吧,不明觉厉的同学暂时还是老老实实的用EventLoop+IO线程池吧~
吐槽下,windows很早以前的的IOCP就是纯异步了…迅雷很早以前都在用…
Reactor模型与Proactor模型
重头戏,先看看 【翻译】两种高性能I/O设计模式(Reactor/Proactor)的比较,到时候我们现场重点聊聊Reactor这个。这里就不描述了,细节太多,问题太多。我希望这里作为大家讨论的重点,而不是现在用文字完全描述。
其次,单个EventLoop循环如果跑在了单个进程/线程中,对于多核服务器来说,是个浪费。多线程和多进程需要注意的一些点还有false sharing等现象和cache的利用以及上下的切换。前者看SMP架构多线程程序的一种性能衰退现象—False Sharing,后者看cpu绑定和cpu亲和性。最后不要忘记了函数重入性与线程安全。
什么,你要代码示例?看这里.
内核级别的优化,来自最近火起来的新浪的FastOS计划内的FastSocket.
Linux服务器程序规范
- 一般以后台守进程形式运行,没有控制终端不接受用户输入。
- 通常有一套日志系统,至少能输出到文件。
- 一般以非root的特殊用户身份运行。
- 通常是可配置的,文件放在/etc下。
- 通常需要在启动的时候生成一个PID文件并存入/var/run目录中,记录该后台进程的PID 。
标准库与第三方库
C/C++相关
太多了,数不胜数,典型的有libev、libevent、libuv、boost asio、cpp-netlib、POCO
太多了,还有各种特殊用途的,比如SSL,DNS异步解析,HTTP相关操作的curl等,不详细说了。
Java相关
标准库就是socket和nio了。
第三方库很多,比如mina、netty等,推荐后者,应用的比较多且比前者效率好些。
Python相关
大名鼎鼎的 Twisted.
如果时间允许,我们还要:
剖析一个流行的开源服务器模型,比如nginx的框架和实现,顺道看看阿里核心系统团队怎么对nginx的数据结构和算法进行的优化~
下一站,分布式系统设计与实现
啥是分布式?别被名字吓到了,分布式的定义如下:
组件分布在联网的计算机上,组件之间通过传递消息进行通信和动作协调的系统。
特性:组件的并发性、缺乏全局时钟、组件故障的独立性
动机:资源共享
挑战:组件异构性、开放性、安全性、可伸缩性、故障处理、并发性、透明性、服务质量。
怎么学?哈哈,我还不会,跟着大牛们摸索,不过分布式两大基础协议之一的一致性哈希算法我介绍过的,这个必须会。
服务器端程序设计就这么一点内容吗?
No, we are too young, too simple.
路很长,现在还远远不是终点,我们欠缺的还有很多!共勉!

