进程眼中的线性地址空间
从文章的题目我们就知道今天是以一个进程的角度来看待自身的运行环境。我们先提出第一个问题,什么是进程?对于这个问题,各种参考资料上给出的定义都显得过于抽象而难以理解,下面是我自己的定义:
进程是一个动态的概念,它是静态的可执行文件执行过程的描述,其包含了一个静态程序运行时的状态和其所占据的系统资源的总和。
还是很抽象吗?那么,我们可以这样比喻,如果说菜谱是程序代码,厨具是硬件的话,那么炒菜的整个过程就是一个进程。这下理解了吧?那我们继续。
每个程序在启动之后都会拥有自己的虚拟地址空间(Virtual Address Space),这个虚拟地址空间的大小由计算机平台决定,具体一点说由操作系统的位数和CPU的地址总线宽度所决定,其中CPU的地址总线宽度决定了地址空间的理论上限(先不考虑主板…)。
比如32位的硬件平台可编址范围就是0x00000000~0xFFFFFFFF,即就是4GB。而64位的硬件平台达到了理论上0x0000000000000000~0xFFFFFFFFFFFFFFFF的寻址空间,即就是17179869184GB的大小(事实上我自己的64位 Intel Core i3 处理器也仅有36位地址总线而已,因为暂时用不到那么大的物理地址范围)。
为了行文的简单,我就以32位硬件平台来描述吧(事实上我对64位所知甚少,不敢信口开河…),同时指定环境为32位的Linux操作系统。
可能看到这里你反而更迷惑了,我一直在说一个进程拥有4GB的线性地址空间(以下只讨论32位),可是操作系统上同时在运行着N个进程,难不成每个都有4GB的线性地址空间不成?没错,每个都有。我们一直在使用术语“线性地址空间”而非“主存储器(内存)”,因为线性地址空间并非和主存等价。我们平时只要一提到“地址”这个概念,想必大家自然而然的就想到了主存储器。但事实上并非线性地址就一定指向主存储器的物理地址,如果你对“线性地址空间”不理解的话,我建议你先去看看我的另一篇博文《基于Intel 80×86 CPU的IBM PC及其兼容计算机的启动流程》。
其实说到线性地址空间,就不得不提到Intel CPU保护模式下的内存分段和分页,但这偏离了文章的主旨。我们暂时只需要知道,之所以进程拥有独立的4GB的虚拟地址,是因为CPU和操作系统提供了一种虚拟地址到实际物理地址的映射机制,在页映射模式下,CPU发出的是虚拟地址,即进程看到的虚拟的地址,经过MMU(Memory Management Unit)部件转换之后就成了物理地址。
好了,下文中我将假定读者理解了线性地址空间的概念,并认可了每个进程拥有4GB线性地址空间这一事实(物理地址扩展(PAE:Physical Address Extension)技术后面再说)。那么,这4GB的线性地址空间里都有些什么呢?我们画一张图来说明一下。
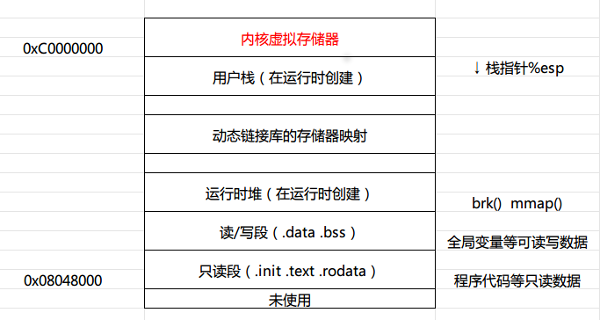
内存高地址区域是被操作系统内核所占据的,Linux操作系统占据了高地址区域的1GB内存(Windows系统默认保留2GB给操作系统,但是可以配置为保留1GB)。如果我们想知道一个进程具体的内存空间布局的话,可以去/proc目录找以进程的pid所命名的目录下一个叫maps的文件,使用cat命令查看即可(需要root权限)。
我们从图中可以看到,32位Linux系统中,代码段总是从地址0x08048000处开始的。数据段一般是在下一个4KB(分页机制默认选择4KB一个内存页)对齐的地址处开始。运行时堆是在数据段之后又一个4KB对齐处开始的,并通过malloc()函数调用向上增长(Linux下的malloc()一般依靠调用brk()或者mmap()系统调用实现)。再接着跳过动态链接库的区域就是进程的运行时栈了,需要注意的是栈是由高地址向着低地址增长的。栈空间再往上就是操作系统保留区域了,用于驻留内核的代码和数据。即就是在一个进程的眼里,只有它和操作系统在一起。
也许你会问,那么一个进程如何修改另外一个进程的运行时数据呢?比如所谓的外挂程序。我们想想,一个进程不知道另一个进程,那谁知道所有的进程呢?操作系统呗,没错,操作系统提供了这种抽象,它也就拥有访问所有进程地址空间的能力。答案就是,一个进程倘若要修改不属于自己的进程空间的数据,就需要操作系统提供相关的系统调用(或API函数)的支持来实现。
我们具体来看看代码段,以C语言为例,程序代码段的入口_start地址处的启动代码(startup code)是在目标文件ctr1.o(属于C运行时库的部分)中定义的,对于特定平台上的C程序都一样。其执行流程如下:
1 | 0x080480c0 <_start>: |
而我们平时写的main函数只是整个C程序运行过程中所调用的一环而已。
我们给出一段代码来看看一个C语言程序编译链接之后如何安排各个元素的内存位置吧,代码和注释如下:
1 |
|
注释中我们看到了各个元素所在内存段的位置。而编译好的main函数本身是存在于代码区的(一般代码段也是只读段)。我们这个程序运行后如果是动态链接的C语言运行时库的话,动态库会存在图示的动态库映射区。其实无论使用C语言运行时库的程序无论有多少,运行时库的代码在内存里只会有一份。对于不同的程序,进行地址映射即可。
接下来我们简单说说栈(stack),关于栈的基本概念到处都是,如果大家不明白可以自己去查查。其实这里的栈就是把一段位于用户线性地址空间最高处的一段连续内存以栈的思想来使用罢了。大家不要觉得线性空间有4GB,栈占据了很大。其实栈大小默认就几MB罢了。Linux可以在终端下执行 ulimit -a命令查看限制。如图所示:
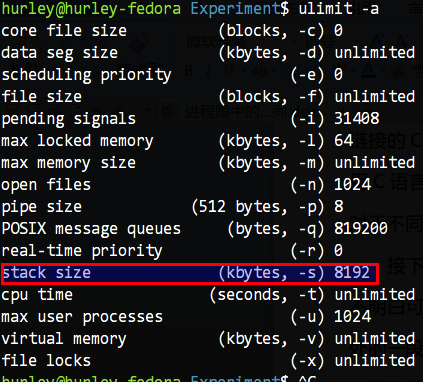
我这里不过也就默认8192KB(8MB)大小,不过可以使用ulimit命令调整(调整只在本次bash执行过程中有效,下次需要重新设置)。
栈也经常被叫做栈帧(Stack Frame)或者活动记录(Activate Record)。栈里通常存储以下内容:
函数的临时变量;
函数的返回地址和参数;
函数调用过程中保存的上下文。
在i386中,使用esp和ebp寄存器划定范围。esp寄存器始终指向栈顶,随着压栈和出栈操作而改变值。ebp寄存器随着调用过程,暂时的指向一个固定的栈位置,便于寻址操作的进行。
我们画一张图来看看吧:
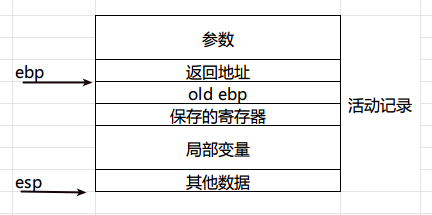
这里照抄网上的函数调用流程:
- 把所有的参数压入栈(有时候是一部分参数,剩余参数通过寄存器传递)
- 把当前指令的下一条指令的地址压入栈
- 跳转到函数体执行
我继续续上后面的操作:
- 在栈里继续创建该函数的临时变量和其他数据
- 函数代码执行完之后栈后退到局部变量之上的位置
- 恢复之前保存的所有寄存器
- 取出原先保存的返回地址,跳转回去
- eax寄存器保存了函数的返回值(浮点数是把返回值放在第一个浮点寄存器上%st(0) )
为了不让大家变的过于纠结,我就不贴出相关的汇编代码了,有兴趣的同学可以自己研究编译器生成的汇编语言。具体方法在《编译和链接那点事》和《浅谈缓冲区溢出之栈溢出》中有详细的描述。
好了,本篇暂时结束,下文以后再说。

